Editor’s Note: This is the first section in a three-part story about the history and regional aspects of sea level rise. Read part two (Anticipating Future Sea Level) and part three (The Known Unknowns of Sea Level Rise).
In August 1849, a farmer named George Thorp noticed some odd, grooved bones poking up from a pile of dirt unearthed by railroad workers building a new line through Charlotte, Vermont. The bone came from a large animal, but not something familiar like a horse or cow. Thorp boxed up the mysterious bone and some others he found in the pile and sent them by wagon to University of Vermont naturalist Zadock Thompson.
After scrutinizing the bones and consulting with leading American and European scientists, Thompson offered an answer: they were whale bones. Specifically, a beluga whale. “How do you get a whale in Vermont?” Thompson wondered. The bones were excavated from a landlocked central part of the state, about 200 feet (60 meters) above sea level and 200 miles (300 kilometers) from the ocean.
It was a question that would occupy some of the greatest scientific minds of the day, recounts Jeff Howe, author of a book about the “Charlotte Whale.” Discovered at a time when little was understood about how or why Earth had ice ages, the whale bones eventually became a key piece of evidence that a huge sheet of glacial ice had once covered much of eastern Canada and New England. The bones also served as a hint of something that wasn’t initially obvious. It was not just higher sea levels put this part of Vermont underwater about 13,000 years ago; the land itself had sunk.
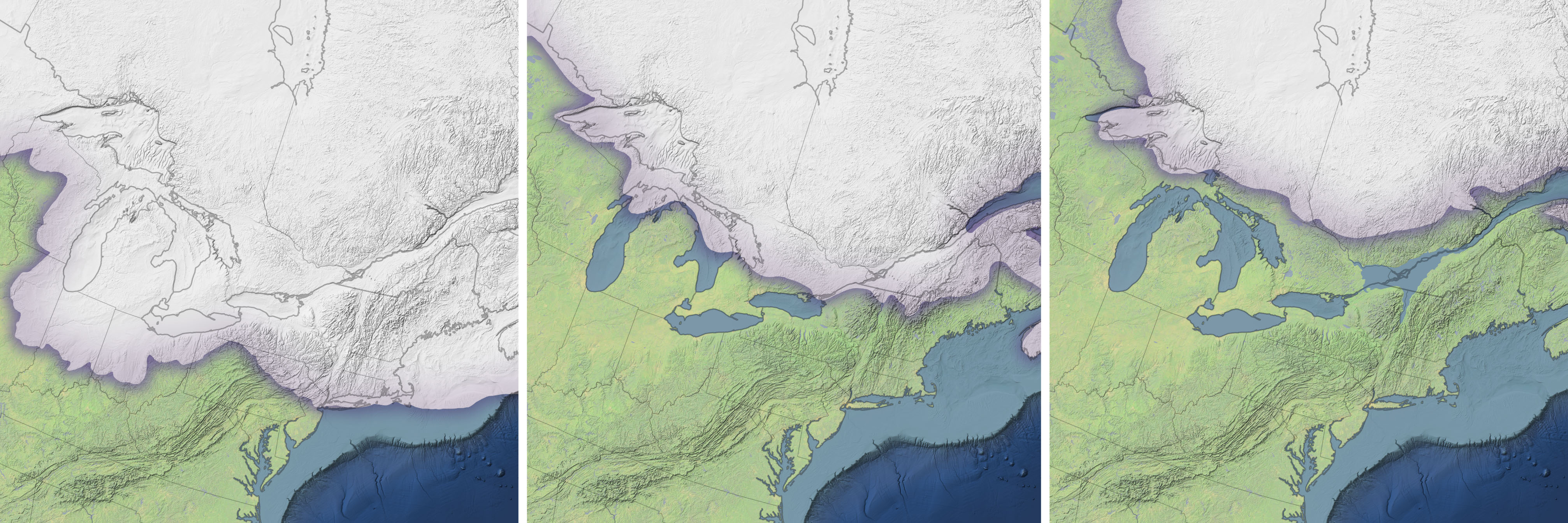
The Laurentide ice sheet covered almost all of Canada and New England at the peak of the last glacial maximum. Like the ice sheets on Antarctica and Greenland today, much of the Laurentide ice sheet was at least one mile thick. Since Earth’s crust sits on a layer of flexible rock in the upper mantle, the immense weight of so much ice would have pushed the Earth’s surface down by hundreds of feet.
“One way to understand what ice sheets do to land masses is to think about what would happen if you put a bag of ice on an inflatable mattress floating in a pool,” explained Jet Propulsion Laboratory geophysicist Erik Ivins. “The mattress—the land—would sag. And the more ice you piled on, the more it would sag.”
After the peak of the glacial maximum, as the climate warmed significantly, the height of the land and sea changed. “A great deal of ice was lost from the global ice sheets during that period—equivalent to about 130 feet (40 meters) of global mean sea level rise,” explained Ivins, who studies past and current sea level rise. As the ice sheet retreated north, ocean water and meltwater inundated the vast depression in the land surface that had been created by the weight of the ice— an area that included the St. Lawrence Valley, southern Quebec, eastern Ontario, and parts of New York. The Champlain Sea was formed.
At its greatest extent, the sea likely covered an area as large as modern Lake Michigan. Its northern shores were flanked by cliffs of towering ice that dropped a steady supply of icebergs into the sea; its southern shores transitioned into marshy tundra and forests. Based on the diversity of fossils found in the fine-grained sediments below it, the Champlain Sea must have teemed with sea life ranging from barnacles and clams to seals and walruses—much like Hudson Bay today.
Subtle shifts in Earth’s orbit called Milankovitch cycles have played a key role in triggering and ending ice ages for millions of years. By about 12,000 years ago, orbital conditions had grown less favorable to ice, pushing Earth into our current warmer, interglacial period known as the Holocene.
“Despite continued melting of glacial ice during the Holocene, sea level rise could not keep up with a competing effect — the rising of the land,” said Ivins. After being pressed down and compressed by so much ice, land surfaces slowly bounced back after the icy weight was lifted. The process—known as glacial isostatic adjustment—occurs slowly because Earth’s crust “floats” on a layer of slow-flowing, partially molten rock called the asthenosphere.
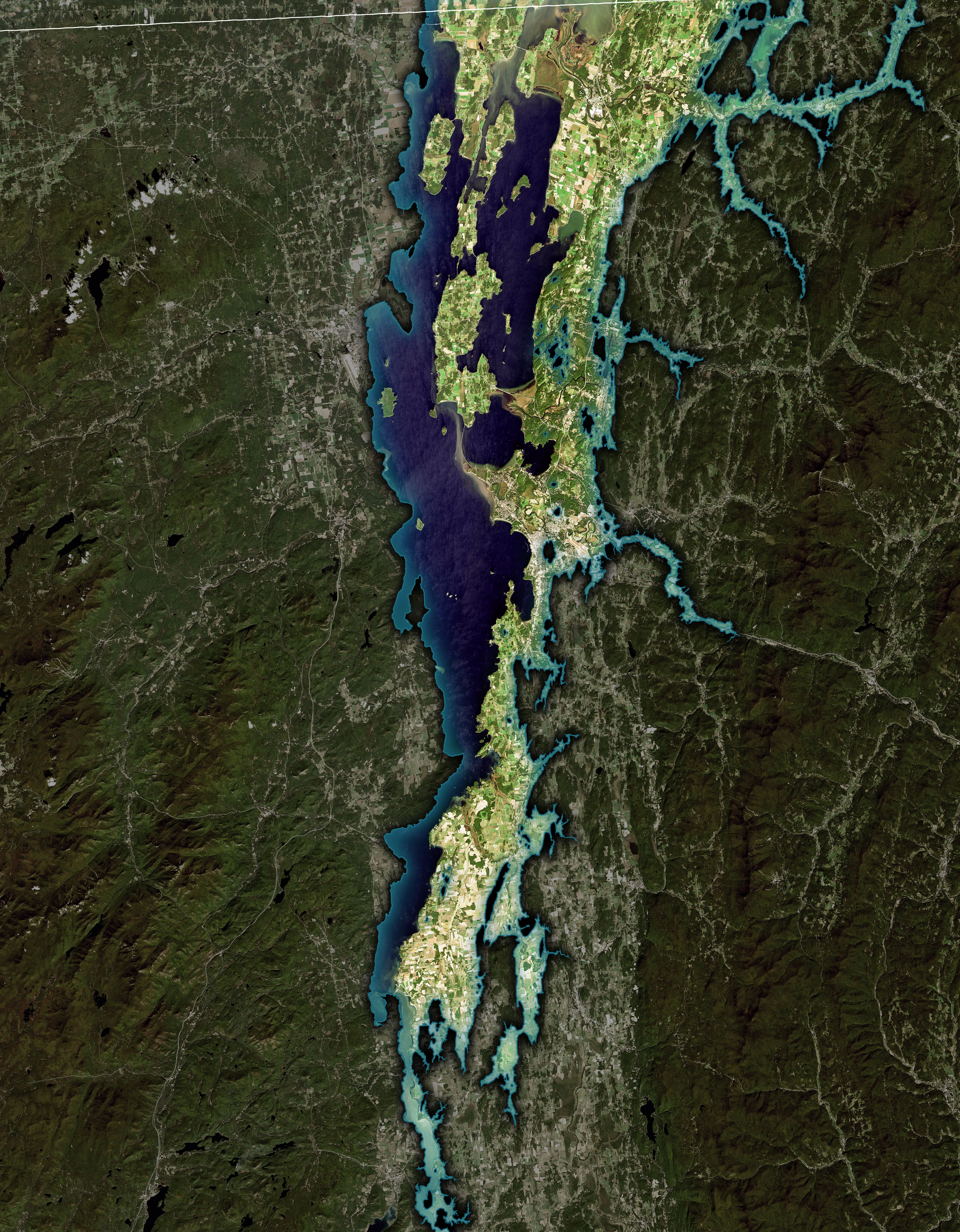
“Eastern Canada was rising about 5 to 8 times faster than sea level between 12,000 and 8,000 years ago. Within a few thousand years, this rising cut the young Champlain Sea off from the Atlantic Ocean, and it slowly began to disappear,” explained Ivins. As the land rose, the Champlain Sea turned first into a series of freshwater lakes. Over time, most of these lakes dried up, though one large relic persists to this day as Lake Champlain.
The uplift of land due to glacial isostatic adjustment continues, though at a slowing rate. Most scientists think the land in New England will take several tens of thousands of years to rebound completely.
NASA Earth Observatory images by Joshua Stevens, using Landsat data from the U.S. Geological Survey, topographic data from the Shuttle Radar Topography Mission (SRTM), bathymetric data from the General Bathymetric Chart of the Oceans (GEBCO), ice sheet records courtesy of Dyke, A. S. (2004), and sea extent data from the Vermont Agency of Natural Resources. Whale drawing courtesy of NOAA. Story by Adam Voiland.